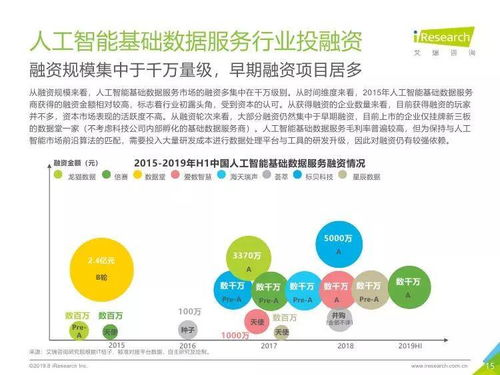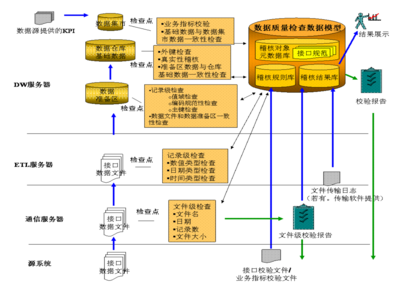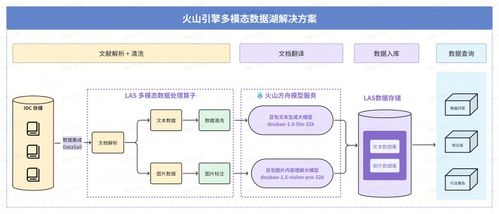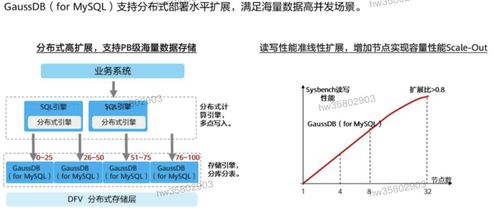
在微服務架構的實踐中,數據一致性一直是一個繞不開的挑戰。許多開發者,即使有多年的編程經驗,在初次面對分布式環境下的數據管理時,也會感到棘手。特別是負責核心邏輯的數據處理服務,其設計和實現直接關系到整個系統的穩定性和可靠性。
從單體應用到分布式難題
在傳統的單體應用中,數據庫事務(ACID)為我們提供了強有力的數據一致性保證。一個業務操作可以在一個數據庫事務中完成,要么全部成功,要么全部回滾,數據始終處于一致狀態。在微服務架構下,業務邏輯被拆分到多個獨立部署、擁有獨立數據庫的服務中。一個完整的業務用例(例如“用戶下單”)可能需要調用訂單服務、庫存服務和支付服務。這時,我們無法再使用傳統的跨數據庫事務。
數據處理服務,往往是這些業務協同中的關鍵一環。它可能負責從消息隊列中消費事件,進行數據轉換、聚合或計算,再寫入數據庫或觸發其他服務。在這個過程中,如何保證“消費的消息”、“處理后的數據”以及“可能觸發的后續操作”這三者之間的最終一致性,是設計的核心。
核心模式:擁抱最終一致性
微服務架構倡導的是最終一致性。這意味著系統允許在某一時刻數據存在短暫的不一致狀態,但通過一系列的設計,保證在沒有新的更新操作后,經過一段時間,所有副本的數據最終會達到一致。對于數據處理服務,以下幾種模式至關重要:
- 事件驅動與事件溯源:這是實現解耦和最終一致性的利器。服務之間通過發布/訂閱領域事件進行通信。例如,當“訂單已創建”事件發布后,數據處理服務可以訂閱該事件,異步地更新自己的數據視圖或生成衍生數據。事件溯源則將狀態的變化記錄為一系列不可變的事件日志,數據處理服務可以基于完整的事件流重建或計算狀態,這為數據一致性提供了可靠的源頭。
- 冪等性設計:在網絡不穩定的分布式環境中,消息重復投遞或接口超時重試是常態。數據處理服務必須被設計成冪等的。這意味著無論同一個操作(或事件)被處理多少次,其結果都應與處理一次相同。實現方式通常是為每個操作攜帶一個唯一的業務ID或請求ID,在處理前先檢查該ID是否已執行成功。
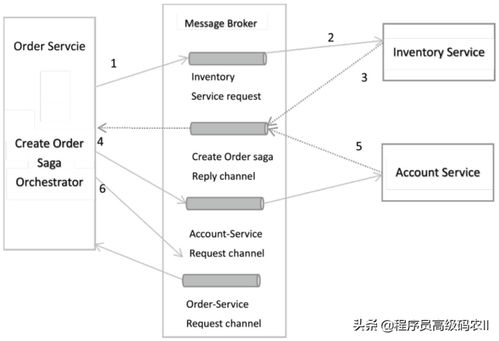
- 事務性消息與補償機制:對于需要強一致性保證的核心場景,可以采用“事務性發件箱”模式。數據處理服務在本地數據庫事務中完成業務操作和“待發送消息”的寫入,然后由一個獨立的“中繼”進程保證消息被可靠地投遞到消息中間件。如果后續服務調用失敗,則需要有補償事務(如Saga模式)來執行反向操作,撤銷之前已完成的操作,使系統回退到一致狀態。
數據處理服務的具體實踐
一個健壯的數據處理服務通常會包含以下組件和流程:
- 可靠的事件消費者:從消息隊列(如Kafka, RabbitMQ)消費事件,并手動或至少一次語義地確認消費位移,確保消息不丟失。
- 冪等處理器:在處理核心邏輯前,通過檢查唯一鍵(如事件ID+業務ID)來過濾重復消息。
- 本地事務邊界:將事件處理與自身數據庫的更新嚴格放在一個數據庫事務中。要么同時成功,要么同時失敗。這是保證服務內部一致性的基礎。
- 異常與重試:對非業務邏輯錯誤(如網絡抖動、數據庫臨時鎖)設計有退避策略的重試機制。對于業務邏輯錯誤,則應將事件投遞至死信隊列進行人工干預或后續修復。
- 監控與可觀測性:通過日志、指標和分布式追蹤,清晰掌握事件的流向、處理延遲和錯誤率,這是運維數據一致性系統的眼睛。
###
理解微服務下的數據一致性,關鍵在于思維的轉變:從強一致性、集中式控制,轉向最終一致性、通過事件進行異步協同。數據處理服務作為這一協同網絡中的“轉換器”和“計算引擎”,其可靠性建立在事件驅動、冪等設計、事務邊界和補償機制這些基石之上。當這些模式內化于心、外化于行時,構建穩定、可擴展的分布式系統便不再是令人頭疼的難題,而是一場充滿挑戰與成就感的工程實踐。